AAAI 2026 | 小鹏联合北大,专为VLA模型定制视觉token剪枝方法,让端到端自动驾驶更高效
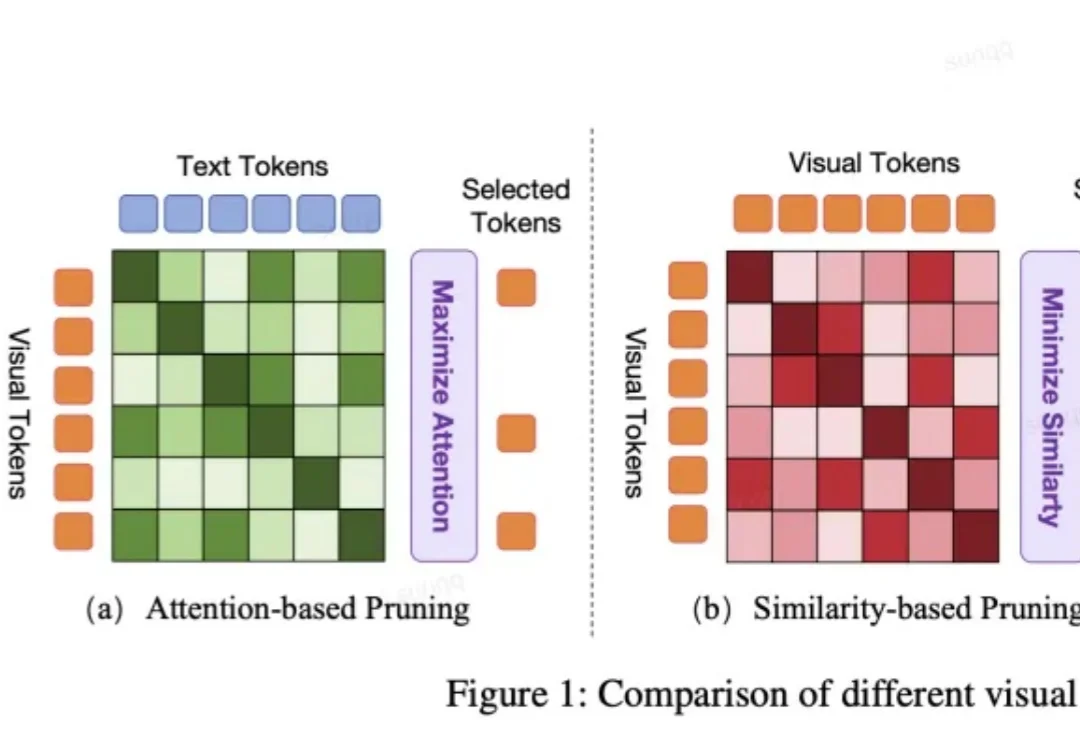
AAAI 2026 | 小鹏联合北大,专为VLA模型定制视觉token剪枝方法,让端到端自动驾驶更高效VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
来自主题: AI技术研报
9425 点击 2026-01-04 15:22